Система STATISTICA полностью
переведена на русский язык и доступна пользователям
Эрнст Статистик
Одна из главных новостей
софтверного рынка в 1999 году — локализация в России
системы STATISTICA, которая, по мнению экспертов, является
идеальным решением для статистического анализа данных на персональном
компьютере. Полностью переведен интерфейс системы, статистические
модули, графика, управление данными, хелп и тома документации. Система
чрезвычайно популярна в мире и насчитывает более 500 000 пользователей.
В STATISTICA реализованы все известные методы статистического анализа
и специализированная статистическая графика для визуального анализа.
Исходные данные и результаты обработки представляются в виде привычных
электронных таблиц (типа Excel), которые помимо обычных средств
работы с данными поддержаны специальными статистическими процедурами
и графиками, а реализованный в системе Статистический советник позволяет
выбрать нужный метод анализа. Система чрезвычайно гибка, открыта
и расширяема: используя среду программирования, пользователь может
написать собственные модули и включить их в систему. Минимальные
требования к компьютеру для работы STATISTICA: IBM PC AT–386 SX20,
4Mb RAM, VGA, Mouse, Windows 95, 20Mb HDD free. Рекомендуемая конфигурация:
P–166, 16Mb RAM, SVGA 800x600x65k, Mouse, FDD, SB, Windows 98/Win
NT 4.0, 250 Mb HDD free.
STATISTICA состоит
из отдельных модулей, каждый из которых является самостоятельным
Windows приложением. В совокупности модули STATISTICA (около 20)
покрывают весь спектр современного анализа данных.
Общий вид переключателя
модулей STATISTICA показан на рисунке 1.
Решаемые на STATISTICA
задачи разбиваются на следующие группы:
· описательная
статистика: компактное описание данных с использованием графики.
Как итог — выработка у пользователя всестороннего представления
и, самое главное, понимания своих данных. Эти методы с успехом
применяются на начальном этапе исследования данных во многих областях:
в медицине, экономике, бизнесе, промышленности, маркетинговых исследованиях,
анализе рекламы, медиа–планировании и т.д. Модуль Основные статистики
и таблицы содержит исчерпывающий набор описательных статистик, таблицы
сопряженности, таблицы флагов и заголовков, кросстабуляцию многомерных
откликов и многомерных дихотомий, вычисление корреляционных матриц,
t–критерии для зависимых и независимых выборок, критерии однородности
дисперсии, однофакторный дисперсионный анализ, Вероятностный калькулятор
(см. рис. 2). Модуль Непараметрические статистики — непараметрические
критерии, ранговые статистики, корреляции Спирмена, Кендалла, гамма,
критерий серий Вальда–Вольфовица, критерий Манна–Уитни, двухвыборочный
критерий Колмогорова–Смирнова, ANOVA Краскелла–Уоллиса и медианный
критерий, критерий знаков, критерий Вилкоксона, ANOVA Фридмена и
конкордация Кендалла, Q критерий Кохрена, вычисление медианы, моды,
геометрического среднего и т.д.;
· установление
зависимостей между данными: самый широкий круг задач в экономике,
промышленности, финансовой деятельности, маркетинге, строительстве
связан с этой проблемой: например, известно применение статистики
при расчете стоимости атомных станций, для анализа отказов на электростанциях;
этот круг задач обычно решается в модулях Множественная регрессия,
Нелинейное оценивание, Моделирование структурными уравнениями. Модуль
Множественная регрессия — пошаговая регрессия с включением
и исключением предикторов, нелинейная регрессия, ридж или гребневая
регрессия, построение прогнозов, всесторонний анализ остатков; можно
анализировать очень большие модели, включающие до 500 переменных;
Нелинейное оценивание — подгонка любой задаваемой пользователем
функции, задаваемая пользователем функция потерь, разрывная регрессия;
Структурное моделирование — процедуры построения структурных
моделей;
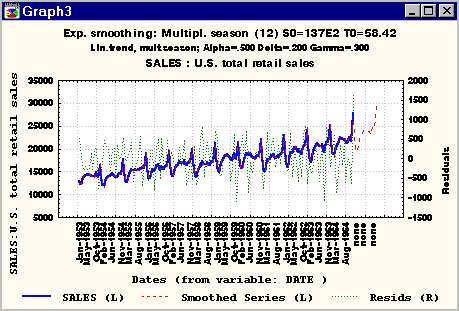
· прогнозирование —
одна из популярных задач, встречаемых на практике, например, прогнозирование
выборов, эффективности рекламной компании, продаж и т.д. Специальный
модуль STATISTICA Анализ временных рядов позволяет строить эффективные
прогнозы с использованием классических, апробированных методов.
Временные ряды и прогнозирование — набор моделей анализа временных
рядов, включая модели авторегрессии и скользящего среднего, модели
с интервенцией, анализ распределенных лагов, спектральный анализ,
преобразования рядов: быстрое преобразование Фурье и другие (см.
рис 3);
· анализ многомерных
данных: факторный анализ, многомерное шкалирование, дисперсионный
анализ, кластерный, дискриминантный анализ, канонический анализ,
деревья классификации и др. Методами многомерного анализа можно
решать, например, следующие задачи: найти конфигурацию системы с
максимально близкими к заданным параметрам или найти группу накопителей
на дисках с нужными средними параметрамию. Модуль Кластерный анализ —
широкий набор процедур кластерного анализа, включая иерархическое
объединение, двухвходовое объединение, метод к–средних; алгоритмы
оптимизированы для анализа очень больших проектов, например, методом
к–средних можно анализировать 400000 наблюдений с 10 переменными;
Факторный анализ — процедуры факторного анализа и анализа главных
компонент, ортогональные и косоугольные факторы, иерархический анализ
косоугольных факторов и др.; Канонический анализ — вычисление
канонических переменных и канонических корней; Многомерное шкалирование —
анализ расстояний, матриц сходств и различия, диаграмма Шепарада
и др.; Деревья классификации — современные методы построения
деревьев классификации с категориальными и порядковыми предикторами
и различными функциями потерь;
· сравнение средних
в различных совокупностях: модуль Дисперсионный анализ — полный
набор методов одномерного и многомерного дисперсионного анализа,
фиксированные и переменные ковариаты, апостериорные критерии, контрасты,
проверка предположений дисперсионного анализа, планы с повторными
измерениями, иерархически вложенные планы, планы с пропущенными
ячейками и другие; модуль Компоненты дисперсии — смешанные
модели дисперсионного анализа, оценка компонент дисперсии.
· анализ больших
таблиц сопряженности, которые часто возникают в маркетинговых исследованиях:
модули Логлинейный анализ и Анализ соответствий;
· отдельной группой
идут задачи промышленной статистики. Особенное развитие эти методы
получили в Японии, США и Германии, где их используют для контроля
качества продукции, организации процедур выборочного контроля, анализ
надежности оборудования и т.д. В STATISTICA имеется специальная
группа модулей Промышленная Статистика, которая, кроме контроля
качества, содержит анализ процессов и планирование экспериментов.
Методы контроля качества предоставляют новые технологии промышленно
развитых стран для тестирования продукции и указание моментов выхода
процессов из–под контроля. При минимальных вложениях методы позволяют
повысить качество продукции;
· чрезвычайно
интересны задачи статистической теории надежности, которая позволяет,
например, рассчитать надежность нефтепроводов и прогнозировать число
порывов, теми же методами решается широкий круг задач, связанных
с оценкой надежности компьютеров, модемов и т.д.
· STATISTICA традиционно
применяется в страховании (анализ таблиц, оценка рисков, страхование
автотранспорта и т.д.); модуль Анализ выживаемости — анализ
таблиц жизни, оценки Каплана–Мейера, регрессионные модели: Кокса,
логнормальная, экспоненциальная, зависящие от времени ковариаты,
разнообразные статистики и критерии;
Пример: прогноз розничных
продаж
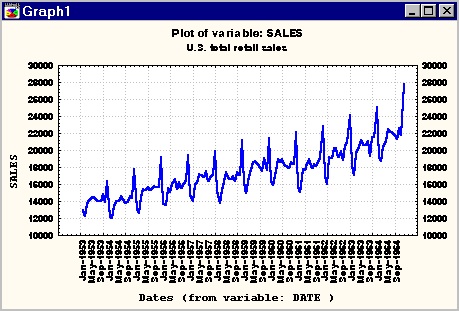
Рассмотрим ряд розничных
продаж (рис. 4):
В ряде имеется отчетливые
пики, приходящиеся на декабрь месяц, объем продаж постепенно возрастает
и, кроме того, что общая картина продаж повторяется из года в год.
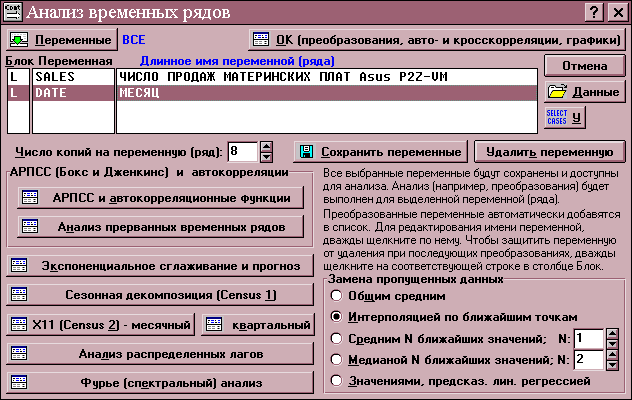
Как спрогнозировать ряд? Это можно сделать в STATISTICA в модуле
анализ временных рядов (рис. 5):
Москва, Б.Трехсвятительский
переулок,
д.3/12, к.418 Тел./факс (095) 916-03-93